In my work I still see people easily spinning up virtual machines in the cloud. For me this is a horrible sight.
I’ve been working for 7 years now in the cloud and never had any use of a virtual machine.
In this blog I will explain why using virtual machines is expensive, inflexible and maintenance heavy. Of course I will offer some alternatives but those details will be explained in follow-up’s. All examples are either general or on AWS cloud, but the same concept applies to others platforms like Azure cloud as well.
Reasons why VM’s are not the right cloud tool
Financial reasons
When running a virtual machine you often see usage graphs like this:
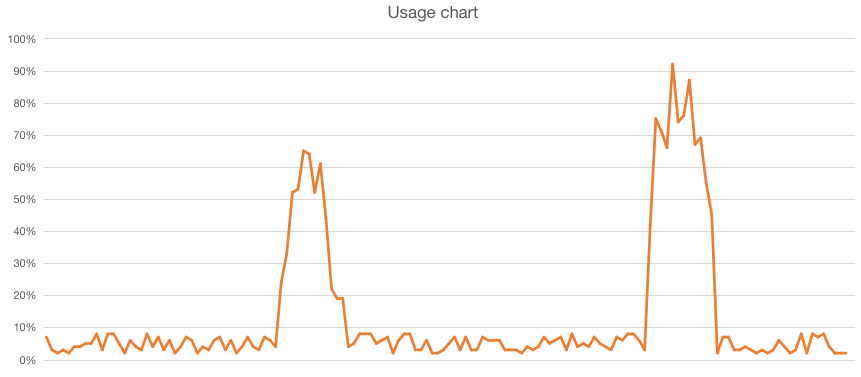
The graph in this case shows a peak during breakfast and diner. The details per use-case will differ but this is a common pattern. Mostly the specifications of the virtual machine are selected in a way so it can perform decently during peak hours. But this means there is a constant over-capacity during low hours.
If you would visualize the unused reserved capacity you end up like this:
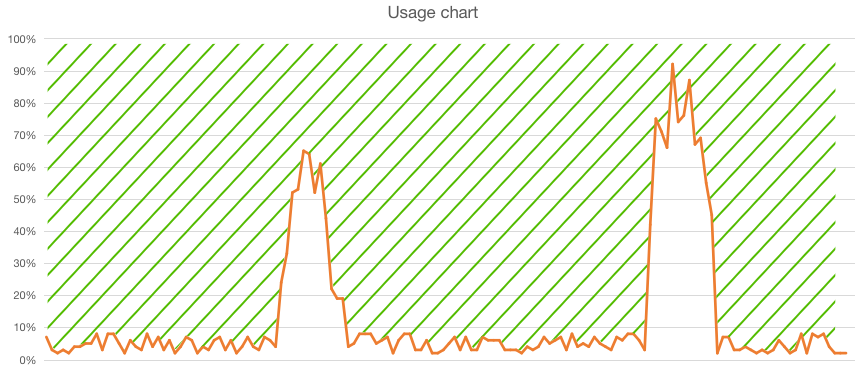
You are still paying for all the unused capacity!
Example: A customer had some (smaller) servers running for around €150,- each month. When going full serverless the monthly costs were dropped to less then €5,- EUR.
Inflexibility reasons
When starting a product, most of the time it is not clear how much capacity is need. Probably during development the smallest instance is used and with some guesstimate the production instance size is decided.
At first this goes well but at one point this might be the usage chart:
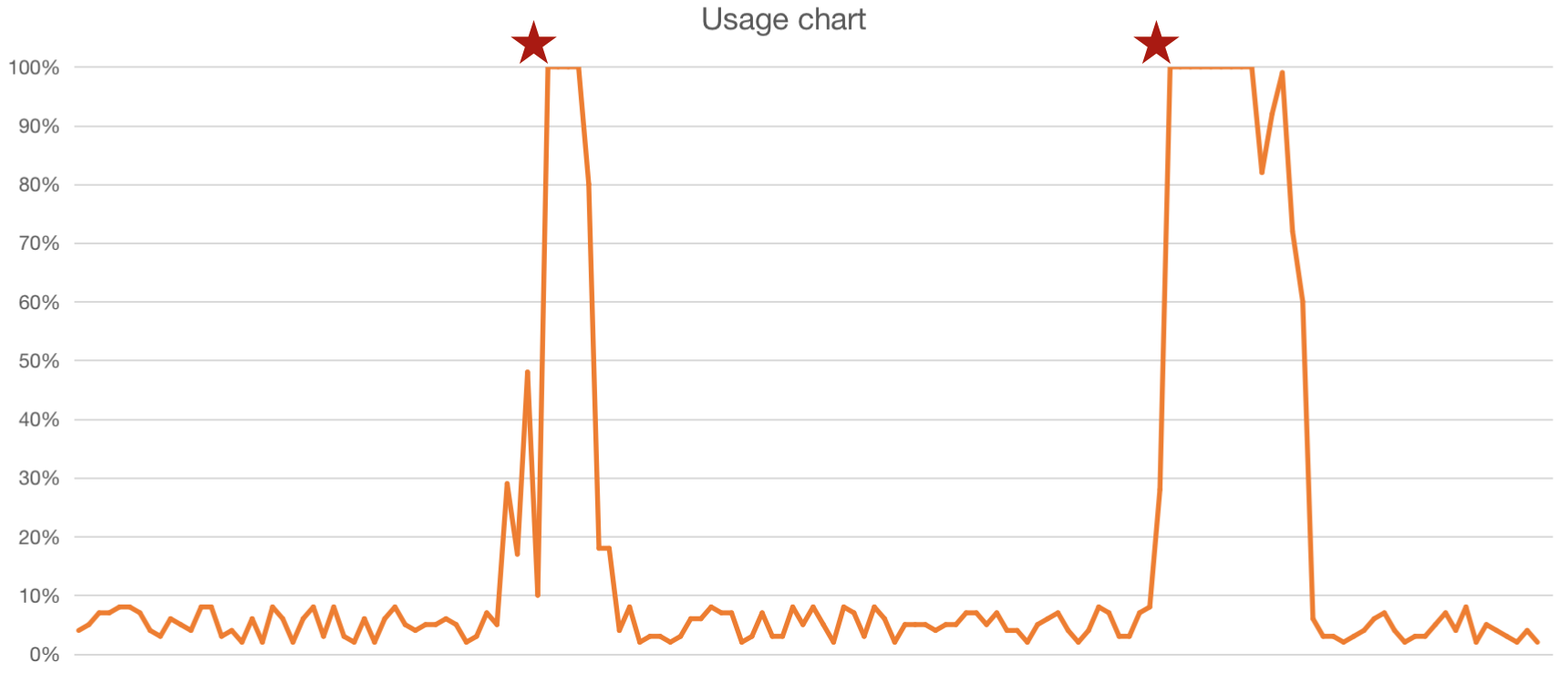
Your application becomes slow during peak moments due to limited capacity.
Just get a bigger instance!
This is probably the start of a more expensive journey. The easy solution is to “jus get a bigger instance”. But as seen in financial reasons this will also increase the amount of over capacity during low hours.
Better would be to scale horizontally and introduce a load balancer which can spin-up multiple smaller instances. But this is not always as simple as it sounds:
- We now need a database server (it was embedded)
- Software is not always designed to share a database connection
- Setting up proper scaling is hard
- A VPC is needed to secure inter-instance traffic
- Session management is terrible: Lets also introduce a mem-cache instance
Security reasons
Running software in a virtual machine actually means 1 credential per outgoing connection. There is no real distinction between all (sub) processes that are running inside the machine. Therefor really fine grained security access is not possible.
Comparison: With a microsystems architecture you can create many fine grained credentials. Here a specific microservice could only read data from the database. Even if the microservice is somehow breached it still can’t modify.
Complexity reasons
Which one looks more complex?
| Cloud | Virtual Machine |
|---|---|
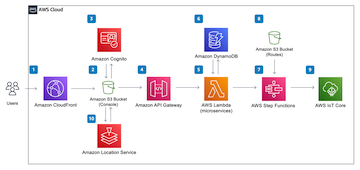 |  |
The left image has more visual components. On the right side my answer would be I don’t know. Knowing whats is in your architecture is very important. In my experience the individual elements on the left side are:
- scalable
- minimal configuration possibilities
- always available
On the right side I have to guess. This could be:
- Database server
- Nginx/Apache server
- Bash scripts
- Cron jobs
- Configuration in /etc /opt /var
- …
Basically its a black box with lots of configuration.
Maintenance reasons
Lets assume during the development phase everything goes smooth, all software has the latest LCM version and a cool automation bash script is build to configure everything.
A lot of virtual machines run 24/7 for many days/weeks/months or even years.
Software needs patching.
Some of the patching is easy enough but others introduce breaking changes. The longer a server is active, the harder and scarier it gets to update the machine.
If a fix need to be applied, people are suddenly confronted with that cool automation bash script which does not make any sense anymore and does not have unit tests.
During the lifetime of a virtual machine you need to have people employed with enough knowledge of server management. They need to have costly night-shifts for that once in a year moment where they need to fix something.
Recap
Above I basically explained why I do not think a virtual machine is ever a good idea. Not for small companies, but also not for large companies. Even in enterprises you can easily save on money with a proper skepticism if people ask for a virtual machine. Between the lines I’ve hinted a bit towards some alternatives. These alternatives probably need a shift in thinking about software but they are worth it. I will spend some blogs on them as well.
What to do with…
Sometimes there are difficulties to take into consideration
Virtual desktop environments
This is probably an ok-ish use-case. However, think about the possibility that it can be done with auto starting and stopping containers.
”Vendor software requires a VM”
Ask the vendor to consider static containers. This already enforces some Infra as Code with i.e. the Dockerfile. Also containers can work with smaller units of work as long as their application is scalable.
When choosing the route of VM
Sometimes you will still use the route of a VM. In that case I do advise the following
1. Leverage machine instances
Create a machine instance per configuration set. This improves stability and speed on startup. Patch the machine images as often as possible.
2. Always use a load balancer
Even with a single node use a load balancer. Make sure you mark the running node “dirty” every day. This will trigger a start of a new node from the predefined machine image with the patched software. Using this approach you are forcing yourself to make the startup perfect. If not you are fixing the misconfiguration every day.
3. Use a cloud orchestration tool
Use cloud tools like terraform, cloudformation/cdk, ARM/bicep to deploy your infra and building your machine images. When properly automated you can easily setup multiple types of tests. Like:
- acceptance test for patched machine images
- Daily Disaster & Recovery (DR) test where you just duplicate the whole cluster
End note
Thanks for reading, I hope it was useful. Please drop me a note on linked in when you have additional questions or remarks.
~ Joost van der Waal (Cloud guru)