In this blog I will go a bit more into the way serverless works underneath the hood. For many people it is not always clear how you should look at these concepts.
Serverless is a Contract of Trust
Serverless is a contract of trust so that we can leave behind all maintenance work and only focus on our own product.
The service model
Before going into serverless we take a look at how the cloud providers offer Services. This works the same across the providers. Lets pick a couple from the hundreds of AWS services:
- EC2 (Virtual machines)
- S3 (Data storage)
- Lambda (Serverless compute)
- API Gateway (Serverless API Management)
- Cognito (Serverless authentication)
- DynamoDB (Serverless no-sql database)
- SQS (Serverless message queues)
What all of these have in common: They do 1 thing very good. Basically every service is a mini company in the cloud provider. They manage a lot of servers and make sure that the offered service runs near-perfect on those.
We have to trust that these servers recieve continues patches and stay secure. Because they know their unit of work very well they can focus on keeping this unit alive all the time.
Side note: This also applies to EC2. The software running the virtual machines needs to be patched and physical servers are added all the time. Your “Running” virtual machine is probably switching physical server on a regular basis.
The serverless model
In the above list I put multiple serverless services. These services also have some common elements:
- Runs on EC2 underneath the hood
- It extracts a speciality from a classical software stack
- Basically worthless on itself
- The unit of work is very small and easy to move
You can expect that for every service the cloud provider runs A LOT of virtual machines. The unit of work is smaller but it is run on one of those machines when the need is there.
Remember this usage chart?
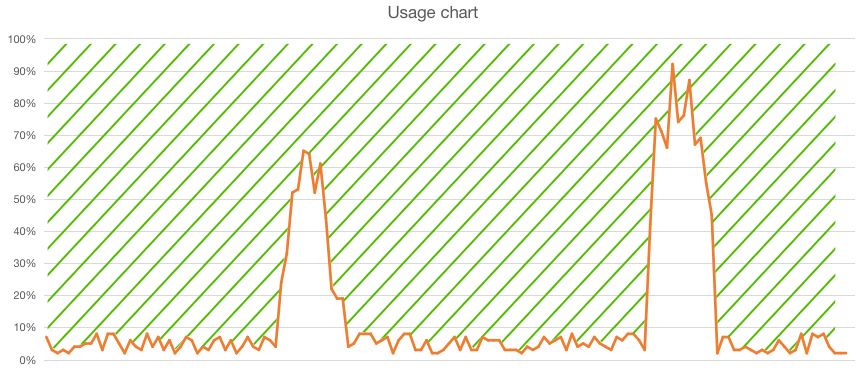
In the serverless model all the green stuff can be utilized efficiently. Due to the scale the service can guarantee:
- performance
- availability
In theory it can just decide to run the unit of work in another physical datacenter when the primary is somehow unavailable.
Security
This is really where the trust part comes into place. Because your unit of work can run on any server or shared server we have to trust that there is a perfect sandbox model in place. Also we have to trust they do not misuse their authorization identity.
Trust comes with the volume
But in this case trust comes with the volume as well. Millions of companies run on these services next to you. Many very skilled people are using this and if something looks wrong people will notice immediatly.
And remember: This is their single point of focus. Manging this correct is the only reason they have a right to exist.
Payment models
Of course serverless comes with a price. Many serverless services charge by usage and/or reserved capacity.
Again looking at the usage graphs:
When we would design a system that would utilize all available space the VM solution would be much cheaper. This however should not be our speciality. We mostly care about our own product.
Conclusion
If you can prevent reserved capacity you can be very cost efficient when only using serverless concepts. When there is little to no activity (which is almost always) you don’t pay at all.
you don’t pay at all
When you have peak usage the service provider can scale up to a level where you can easily serve millions of users without latency.
End note
Thanks for reading, I hope it was useful. Please drop me a note on linked in when you have additional questions or remarks.
~ Joost van der Waal (Cloud guru)